SuperCLUE-Video
SuperCLUE-Video: 中文原生多层次文生视频测试基准
SuperCLUE-Video
中文原生多层次文生视频测评基准
近年来,自然语言处理和计算机视觉领域见证了如ChatGPT/GPT-4和Stable Diffusion/Midjourney等大型模型的飞跃发展,它们在文本和图像生成方面的能力令人瞩目。 多模态模型,特别是在将文本描述转换成图像内容的应用中,显示出其强大的应用潜力。
随着技术的进步,文生视频(Text-to-Video)的研究和应用也在全球范围内蓬勃发展。例如,OpenAI推出的Sora模型便能根据文本创建逼真的视频内容, 这类技术在短视频制作、影视制作、广告和娱乐行业等领域具有巨大的应用潜力和商业价值。
目前已经存在一些英文的文生视频基准,如VBench、FETV和EvalCrafter,可以用于评测英文文生视频模型的性能。然而,针对中文文生视频大模型的基准测试还比较缺乏,无法直接评估中文文生视频大模型的质量和效果。中文文生视频技术正处在快速发展的阶段,为了推动这方面的发展,需要建立一个专门针对中文大模型的基准测试。
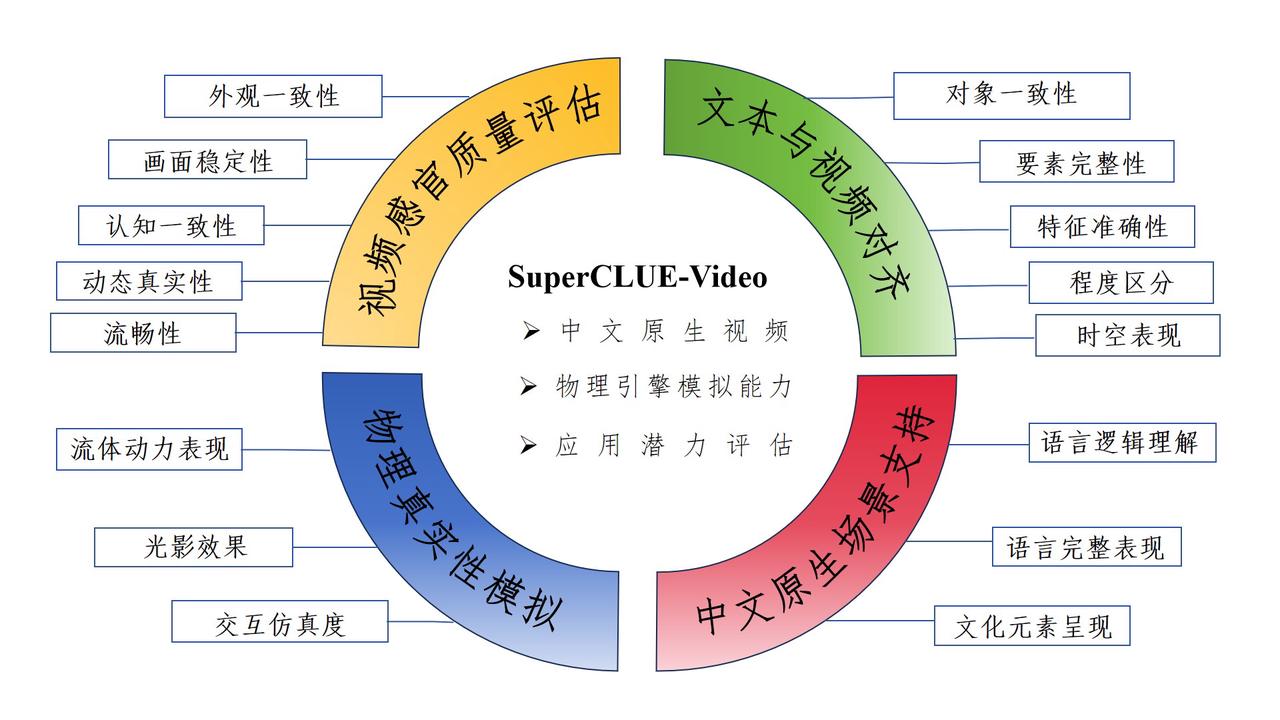
为应对现有挑战,我们推出了中文专用的多层次文生视频基准测试——SuperCLUE-Video(简称SC-Video)。SC-Video旨在通过一系列详尽的评估指标和测试数据集,全面衡量中文视频生成模型在生成质量、多样性及一致性等方面的性能。其设计融合了国际基准的架构及针对中文环境的特殊需求,旨在促进中文视频生成领域的研究、开发与技术创新。
项目地址:https://github.com/CLUEbenchmark/SuperCLUE-Video
推文地址:https://mp.weixin.qq.com/s/bZD4nBYadbr_CvH1IvfO5w
文章地址:www.CLUEbenchmarks.com/superclue_video.html

提示词:几头巨大的长毛猛犸象踏过雪地草甸缓缓而行,它们那长长的毛发在微风中轻轻飘扬, 远处覆盖着雪的树木和壮观的雪顶山峰,午后的光线透过朵朵薄云,阳光高挂在远方,营造出一片温暖的光晕。 低角度的镜头非常惊艳,捕捉到这些大型毛茸茸哺乳动物的美丽镜头,景深效果显著。

提示词:一段庆祝中国农历新年的视频,里面有舞龙表演。
立足于为通用人工智能时代提供中文世界基础设施,文字输入或prompt提示词都是中文原生的,不是英文或其翻译版本; 并充分体现中文世界的场景和特点。比如识别并融入我国的习俗和文化元素,比如为春节设计具有中国风的视频贺卡,不仅展现了图像美学, 也蕴含了丰富的文化内涵。
考察大模型对物理规律的学习能力,包括对物体运动、重力、惯性等物理现象的模拟能力;观察模型生成的视频中是否能准确地呈现出物理规律,
如飘逸的毛发、水体波纹等。具体可以包括:
1)动态模拟技术:利用物理引擎模拟衣物摆动、头发飘逸等效果,增强角色真实感;
2)水面动画:精确模拟海浪、水波等水体效果,为场景带来生动的视觉体验;
3)物体交互:展示物体间的碰撞和互动,用于展现产品特性或动作场面的真实性;
4)自然现象:再现风、雨、雷电等自然现象,为影视作品增添戏剧性和视觉冲击力;
5)特效与CGI:依据物理规律创造逼真的爆炸、破坏等特效,提升观众沉浸感。
针对重点领域,影视、短视频、广告、娱乐等,展开评估。
考察的场景,如在提供符合中文语境的创意脚本生成、本土化的品牌营销策略、为娱乐内容添加独特的中文文化内涵及地域文化的特色元素设计等方面。

参考SuperCLUE-Auto细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息。
中文prompt构建流程:
1.参考现有prompt--->2.中文prompt撰写--->3.测试--->4.修改并确定中文prompt
参考国际标准和当前已有工作,针对每一个维度构建专用的测评集。
评估流程:
1.获得<中文prompt,视频帧>-->2.依据评估标准-->3.使用评分规则-->4.进行细粒度打分
结合超级模型,在定义的指标体系里明确每一个维度的评估标准。结合评估流程、评估标准、评分规则,将文本输入、视频帧(图像)送入超级模型进行评估,并获得每一个维度的评估结果。
进行评估与人类一致性分析,并报告一致性表现。
比如,针对雪地巨象漫步在午后阳光下的冬日仙境这个视频的【文本与视频对齐】这个一级维度,使用对象一致性、要素完整性、特征准确性、程度区分、时空表现四个具体维度进行评估。
具体的说:
在对象一致性中,大象外观“体型”是否保持一致;要素完整性中,是否出现了“多头”大象;特征准确性中,是否有存在“雪地”;程度区分中,大象是“行走速度”如何(缓缓而行);时空表现中,大象的“毛发飘扬”是否顺着时间展开有所体现。

提示词:几头巨大的长毛猛犸象踏过雪地草甸缓缓而行,它们那长长的毛发在微风中轻轻飘扬...
1. 外观一致性:视频中对象的形态特征应一致,如人物外貌、服饰,物体外形等。
- 例如,视频全程人物的衣着应保持不变。
2. 画面稳定性:视频画面要尽可能减少噪点和失真。
- 如,避免在转场时出现画面闪烁。
3. 认知一致性:色彩、边界清晰,整体布局美观。
- 即,颜色搭配应自然,场景布局和谐。
4. 动态真实性:视频应展现真实的动态效果,与静态图像有清晰区分。
- 例如,人物行走动作流畅自然。
5. 流畅性:对象移动和场景变换过渡自然,无明显断层。
- 如,摄像机平移时背景应连续无跳跃。
1. 对象一致性:视频需根据文本生成准确的对象。
- 例如,“行走的人”应呈现为人而非其他生物。
2. 要素完整性:视频应全面反映文本描述的内容。
- 如,若文本提及“一群人”,视频应展现多个人物。
3. 特征准确性:视频中应准确体现文本描述的特征。
- 例如,文中提到“红色”,视频应展示相应的红色物体。
4. 程度区分:视频应体现文本中描述词的强度差异。
- 如,“快速行驶的车”与“飞速行驶的车”应有速度上的明显区别。
5. 时空表现:视频准确展现文本中事件的时序和空间关系。
- 例如,若文本描述先后发生的事件,视频应按此顺序呈现。
1. 流体动力表现:视频应准确模拟流体运动,如云雾、水流。
- 例如,流水应模拟真实的水流动态。
2. 光影效果:逼真模拟不同光线条件下的光影效果。
- 如,不同时间的阳光照射应有不同的阴影变化。
3. 交互仿真度:视频中物体间的互动应如同真实世界。
- 例如,摔碎的玻璃杯应呈现碎裂飞溅的效果。
1. 语言逻辑理解:模型应准确掌握中文语序和场景描述。
-例如,正确解析“乌云盖顶,即将下雨”的描述,生成即将降雨的景象。
2. 语义完整表现:模型应理解并展现成语、俗语的含义。
- 如,“载歌载舞”应呈现欢快舞蹈的场景。
3. 文化元素呈现:视频中应准确体现中文文化元素。
- 例如,“庆春节”应展示有灯笼、窗花等装饰的场景。
报名:2月26日----4月1日
参测模型确认:4月1日
测评执行:4月1日--4月19日
测评结果统计:4月22--4月底
测评报告发布:4月底
1. 邮件申请
2. 意向沟通
3. 参测确认与协议流程
4. 提供测评API接口或大模型
5. 获得测评报告
申请评测
邮件标题:SuperCLUE-Video测评申请,发送到contact@superclue.ai
请使用单位邮箱,邮件内容包括:单位信息、文生视频大模型简介、联系人和所属部门、联系方式


1.OpenAI的Sora技术报告
2.Vbench论文
3.FETV论文
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation(NIPS已发表)
4.EvalCrafter
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models,
5.超长文本测评征集文章
SuperCLUE-200K:中文超长文本基准测评!诚邀“大海捞针”!
6.代码测评文章发布文章
SuperCLUE-Code3:中文原生等级化代码能力测评基准
SuperCLUE中文大模型排行榜(2023年7月)
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| - | GPT-4 | OpenAI | 70.89 | 70.04 | 72.67 | 69.96 | 专有服务 |
| 🏅 | 文心一言(v2.2.0) | 百度 | 62.00 | 61.11 | 71.38 | 53.50 | 专有服务 |
| - | Claude-2 | Authropic | 60.94 | 62.01 | 61.18 | 59.63 | 专有服务 |
| - | gpt-3.5-turbo | OpenAI | 59.79 | 64.40 | 63.19 | 51.78 | 专有服务 |
| 🥈 | ChatGLM-130B | 清华大学&智谱AI | 59.35 | 53.78 | 71.39 | 52.89 | 专有服务 |
| 🥉 | 讯飞星火(v1.5) | 科大讯飞 | 58.02 | 63.32 | 65.72 | 45.03 | 专有服务 |
| - | Claude-instant-v1 | Authropic | 56.31 | 58.85 | 55.91 | 54.16 | 专有服务 |
| 4 | 360智脑(4.0) | 360 | 55.04 | 56.68 | 62.54 | 45.88 | 专有服务 |
| 5 | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 6 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 7 | MiniMax-abab5.5 | MiniMax | 53.06 | 53.61 | 62.79 | 42.77 | 专有服务 |
| 8 | 通义千问(v1.0.3) | 阿里巴巴 | 51.52 | 52.84 | 61.73 | 39.98 | 专有服务 |
| 9 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 10 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 11 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 12 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 13 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 14 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 15 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 16 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |
2023年7月SuperCLUE基础能力榜单
| 排名 | 模型 | 平均分 | 语义理解 | 闲聊 | 对话 | 角色扮演 | 知识与百科 | 生成与创作 | 逻辑与推理 | 代码 | 计算 | 安全 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 85.03 | 90.17 | 71.53 | 77.99 | 82.19 | 97.44 | 68.79 | 90.55 | 90.45 | 94.97 | 86.22 |
| - | gpt-4 | 70.04 | 82.91 | 46.77 | 66.39 | 63.46 | 92.65 | 66.67 | 60.33 | 85.45 | 61.48 | 73.02 |
| - | gpt-3.5-turbo | 64.40 | 87.18 | 45.16 | 65.57 | 60.58 | 85.29 | 72.36 | 42.98 | 72.73 | 38.52 | 72.22 |
| 🏅️ | 讯飞星火(v1.5) | 63.32 | 78.26 | 45.90 | 59.84 | 55.88 | 73.48 | 54.92 | 54.70 | 60.00 | 76.86 | 71.54 |
| - | Claude-2 | 62.01 | 83.49 | 49.59 | 57.14 | 52.88 | 78.68 | 68.07 | 53.72 | 66.06 | 44.26 | 65.60 |
| 🥈 | 文心一言(v2.2.0) | 61.11 | 81.90 | 46.34 | 56.67 | 59.80 | 86.76 | 47.73 | 36.52 | 65.79 | 52.63 | 70.63 |
| - | Claude-instant-v1 | 58.85 | 76.52 | 50.00 | 58.20 | 55.77 | 77.04 | 61.48 | 40.00 | 66.97 | 33.61 | 67.77 |
| 🥉 | 360智脑(4.0) | 56.68 | 76.92 | 52.46 | 58.33 | 54.08 | 76.80 | 61.54 | 37.29 | 53.64 | 29.57 | 67.92 |
| 4 | ChatGLM2-6B | 55.60 | 74.36 | 44.35 | 55.74 | 56.73 | 76.47 | 51.22 | 40.50 | 41.82 | 45.08 | 66.67 |
| 5 | internlm-chat-7b | 54.85 | 80.34 | 48.39 | 55.74 | 55.77 | 77.94 | 36.59 | 37.19 | 51.82 | 34.43 | 68.25 |
| 6 | ChatGLM-130B | 53.78 | 70.94 | 45.97 | 56.56 | 61.54 | 75.74 | 55.28 | 29.75 | 45.45 | 31.15 | 63.49 |
| 7 | MiniMax-abab5.5 | 53.61 | 79.49 | 45.97 | 59.84 | 60.58 | 85.29 | 47.97 | 29.75 | 30.00 | 31.97 | 61.11 |
| 8 | 通义千问 | 52.84 | 74.77 | 45.97 | 57.98 | 53.00 | 76.69 | 38.89 | 33.06 | 46.67 | 39.67 | 60.40 |
| 9 | Baichuan-13B-Chat | 50.46 | 64.10 | 41.94 | 50.00 | 52.88 | 75.00 | 57.72 | 27.27 | 40.91 | 31.15 | 60.32 |
| 10 | BELLE-13B | 48.71 | 68.38 | 46.77 | 51.64 | 53.85 | 64.71 | 25.20 | 32.23 | 48.18 | 31.97 | 63.49 |
| 11 | IDEA-姜子牙-13B-v1.1 | 47.55 | 70.09 | 49.19 | 48.36 | 48.08 | 58.82 | 32.52 | 34.71 | 21.82 | 45.08 | 63.49 |
| 12 | Phoenix-7B | 45.39 | 66.67 | 41.94 | 43.44 | 43.27 | 55.15 | 44.72 | 31.41 | 36.36 | 33.61 | 55.56 |
| 13 | MOSS-16B | 37.01 | 54.70 | 39.52 | 40.16 | 45.19 | 35.29 | 34.96 | 24.79 | 32.73 | 27.05 | 37.30 |
| 14 | Llama-2-13B-chat | 35.85 | 52.14 | 41.94 | 40.98 | 32.69 | 33.82 | 38.21 | 28.93 | 23.64 | 27.05 | 38.10 |
| 15 | Vicuna-13B | 34.61 | 49.57 | 33.06 | 32.79 | 37.50 | 25.74 | 30.89 | 27.27 | 40.91 | 35.25 | 35.71 |
| 16 | RWKV-7B-World-CHNtuned | 30.71 | 31.62 | 20.16 | 22.13 | 26.92 | 27.21 | 23.58 | 22.31 | 36.36 | 60.66 | 36.51 |
2023年7月SuperCLUE中文特性榜单
| 排名 | 模型 | 平均分 | 字形和拼音 | 字义理解 | 句法分析 | 文学 | 诗词 | 成语 | 歇后语 | 方言 | 对联 | 古文 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | 82.29 | 96.01 | 83.15 | 62.71 | 91.47 | 90.79 | 92.38 | 83.78 | 69.21 | 70.00 | 83.40 |
| - | gpt-4 | 72.67 | 62.83 | 68.07 | 85.48 | 88.08 | 75.68 | 95.12 | 70.15 | 38.40 | 71.52 | 67.31 |
| 🏅️ | ChatGLM-130B | 71.39 | 48.67 | 68.07 | 75.00 | 83.44 | 84.68 | 95.94 | 67.16 | 45.60 | 70.86 | 72.12 |
| 🥈 | 文心一言(v2.2.0) | 71.38 | 59.34 | 70.34 | 73.33 | 86.58 | 82.88 | 95.12 | 60.31 | 37.60 | 71.03 | 73.79 |
| 🥉 | 讯飞星火(v1.5) | 65.72 | 47.32 | 68.38 | 77.42 | 72.03 | 69.09 | 89.43 | 59.85 | 35.77 | 71.23 | 63.46 |
| 4 | ChatGLM2-6B | 63.59 | 45.13 | 60.50 | 66.13 | 78.81 | 63.06 | 89.43 | 64.18 | 33.60 | 64.24 | 66.35 |
| - | gpt-3.5-turbo | 63.19 | 46.02 | 69.75 | 75.81 | 75.50 | 57.66 | 89.43 | 55.97 | 36.00 | 57.62 | 66.35 |
| 5 | MiniMax-abab5.5 | 62.79 | 46.90 | 57.98 | 63.71 | 75.50 | 71.17 | 86.99 | 60.45 | 41.60 | 58.94 | 62.50 |
| 6 | 360智脑(4.0) | 62.54 | 45.45 | 63.83 | 63.53 | 71.43 | 70.73 | 97.06 | 60.47 | 38.46 | 64.96 | 73.21 |
| 7 | 通义千问 | 61.73 | 41.59 | 60.87 | 60.66 | 73.65 | 67.89 | 88.24 | 51.91 | 40.68 | 68.97 | 57.89 |
| 8 | internlm-chat-7b | 61.35 | 41.59 | 58.82 | 62.10 | 76.16 | 68.47 | 86.18 | 61.94 | 32.80 | 57.62 | 65.38 |
| - | Claude-2 | 61.18 | 48.67 | 70.94 | 70.16 | 67.55 | 54.05 | 83.74 | 58.21 | 36.00 | 60.67 | 59.62 |
| - | Claude-instant-v1 | 55.91 | 43.36 | 62.16 | 72.13 | 62.91 | 50.91 | 84.87 | 47.73 | 31.20 | 56.38 | 45.19 |
| 9 | Baichuan-13B-Chat | 55.38 | 45.13 | 58.82 | 50.81 | 73.51 | 70.27 | 75.61 | 47.01 | 33.60 | 44.37 | 54.81 |
| 10 | BELLE-13B | 52.99 | 42.48 | 55.46 | 67.74 | 56.29 | 46.85 | 78.05 | 38.06 | 33.60 | 59.60 | 49.04 |
| 11 | IDEA-姜子牙-13B-v1.1 | 48.61 | 28.32 | 54.62 | 51.61 | 56.29 | 51.35 | 63.41 | 42.54 | 36.00 | 48.34 | 51.92 |
| 12 | Phoenix-7B | 44.62 | 30.09 | 51.26 | 43.55 | 51.66 | 45.95 | 65.85 | 35.07 | 32.00 | 45.03 | 44.23 |
| 13 | MOSS-16 | 38.01 | 32.74 | 43.70 | 36.29 | 40.40 | 32.43 | 60.98 | 32.09 | 31.20 | 31.13 | 40.38 |
| 14 | Llama-2-13B-chat | 37.37 | 31.86 | 40.34 | 49.19 | 37.75 | 33.33 | 43.90 | 32.09 | 32.00 | 33.77 | 40.38 |
| 15 | Vicuna-13B | 33.71 | 21.24 | 34.45 | 45.16 | 29.14 | 22.52 | 33.33 | 36.57 | 22.40 | 49.67 | 38.46 |
| 16 | RWKV-7B-World-CHNtuned | 28.13 | 25.66 | 26.05 | 25.00 | 29.80 | 26.13 | 45.53 | 17.16 | 20.00 | 36.42 | 27.88 |
2023年7月SuperCLUE开源榜单
| 排名 | 模型 | 机构 | 总分 | 基础能力 | 中文特性 | 学术专业 | 许可证 |
|---|---|---|---|---|---|---|---|
| 🧝 | 人类 | CLUE | 83.66 | 85.03 | 82.29 | - | - |
| 🏅️ | internlm-chat-7b | 上海AI实验室与商汤 | 53.91 | 54.85 | 61.35 | 45.53 | 开源-可商用 |
| 🥈 | ChatGLM2-6B | 清华大学&智谱AI | 53.85 | 55.60 | 63.59 | 42.37 | 开源-可商用 |
| 🥉 | Baichuan-13B-Chat | 百川智能 | 49.35 | 50.46 | 55.38 | 42.21 | 开源-可商用 |
| 4 | BELLE-LLaMA-13B-2M-enc | 链家 | 46.60 | 48.71 | 52.99 | 38.10 | 开源-非商用 |
| 5 | IDEA-姜子牙-13B-v1.1 | 深圳IDEA研究院 | 43.80 | 47.55 | 48.61 | 35.26 | 开源-非商用 |
| 6 | phoenix-7B | 香港中文大学 | 41.57 | 45.39 | 44.62 | 34.70 | 开源-可商用 |
| 7 | MOSS-16B | 复旦大学 | 35.36 | 37.01 | 38.01 | 31.07 | 开源-可商用 |
| 8 | Llama-2-13B-chat | Meta | 34.26 | 35.85 | 37.37 | 29.57 | 开源-可商用 |
| 9 | Vicuna-13B | UC伯克利 | 31.70 | 34.61 | 33.71 | 26.80 | 开源-非商用 |
| 10 | RWKV-7B-World-CHNtuned | RWKV基金会 | 27.83 | 30.71 | 28.13 | 24.66 | 开源-可商用 |