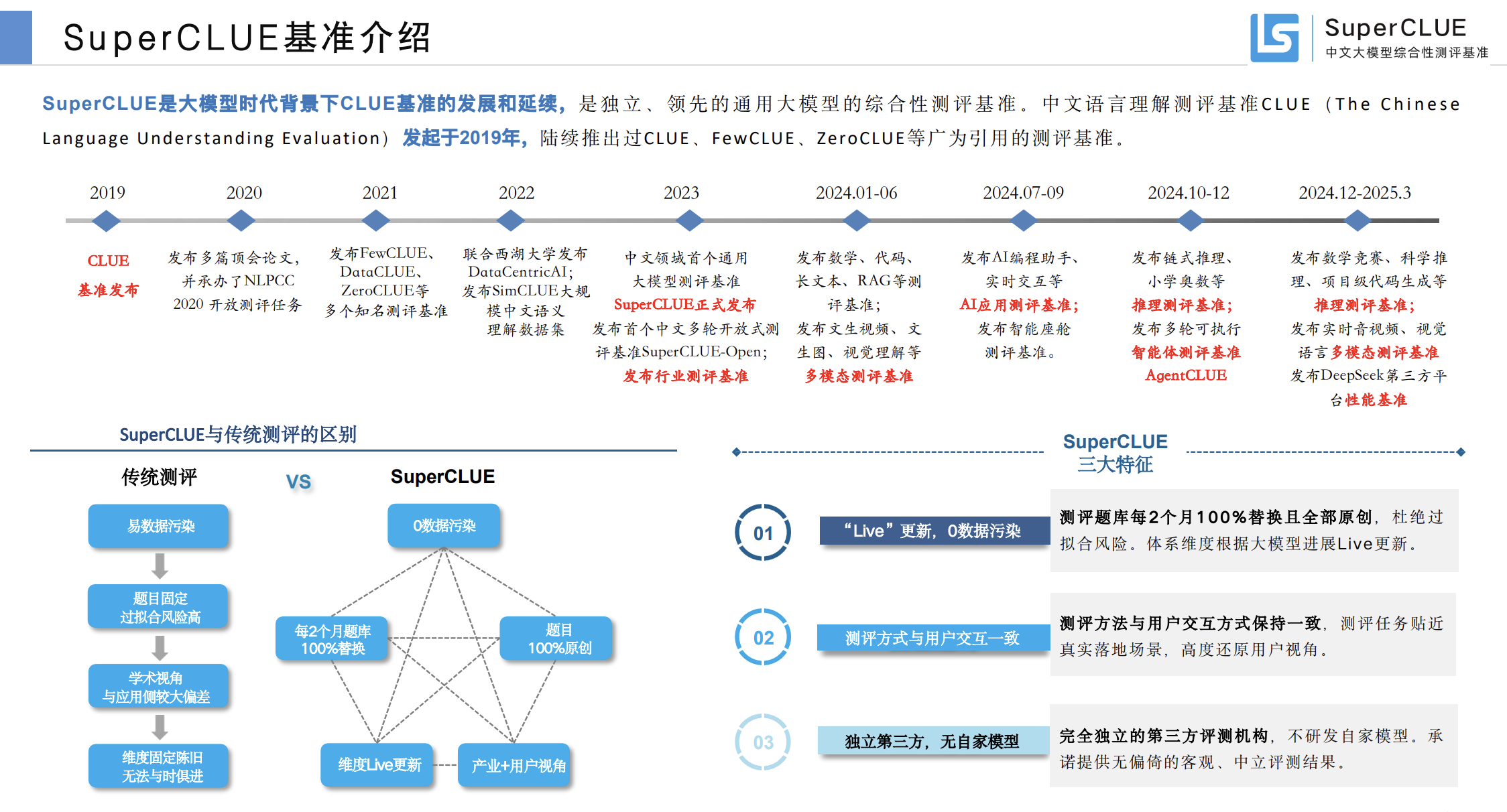
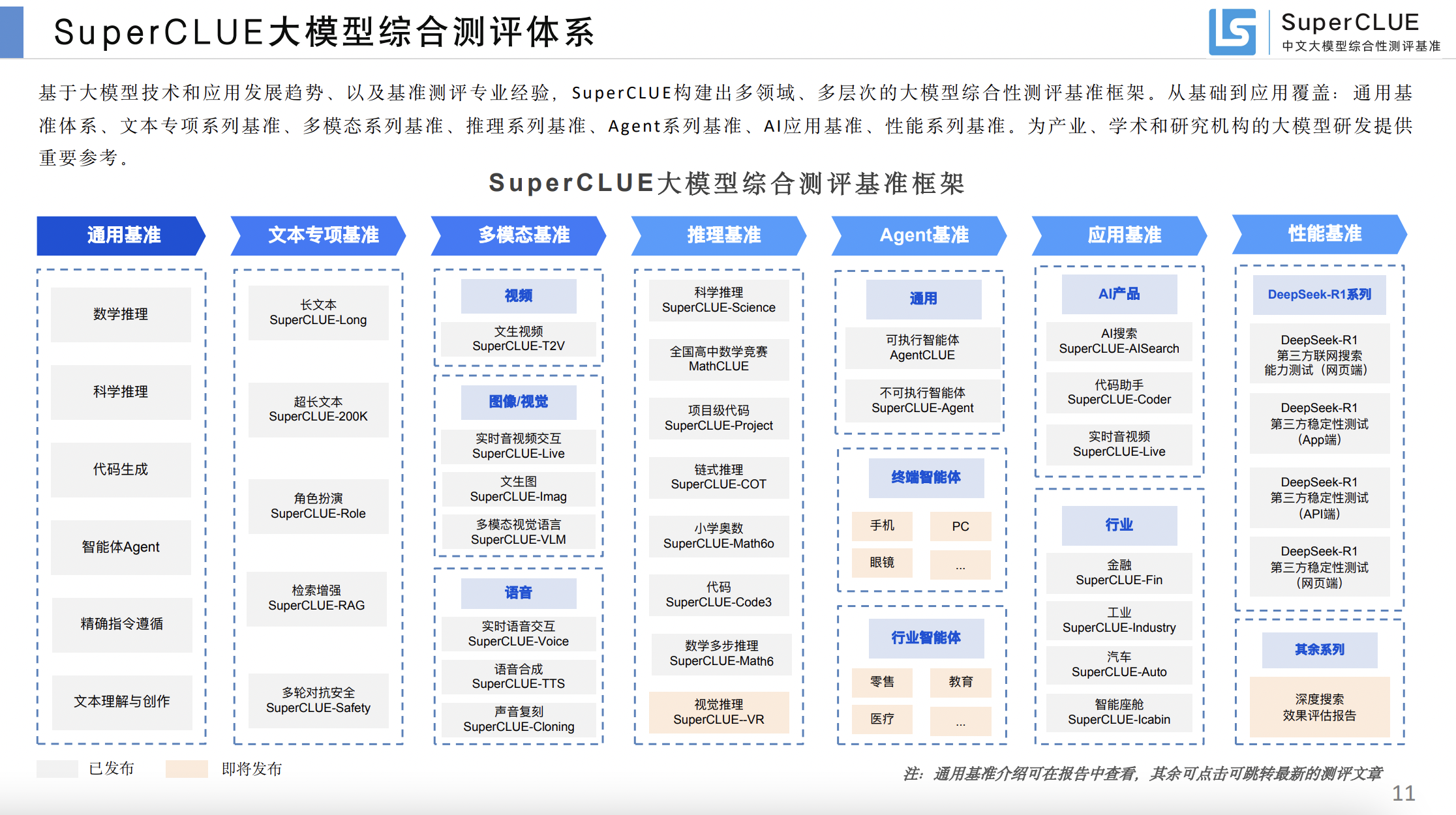
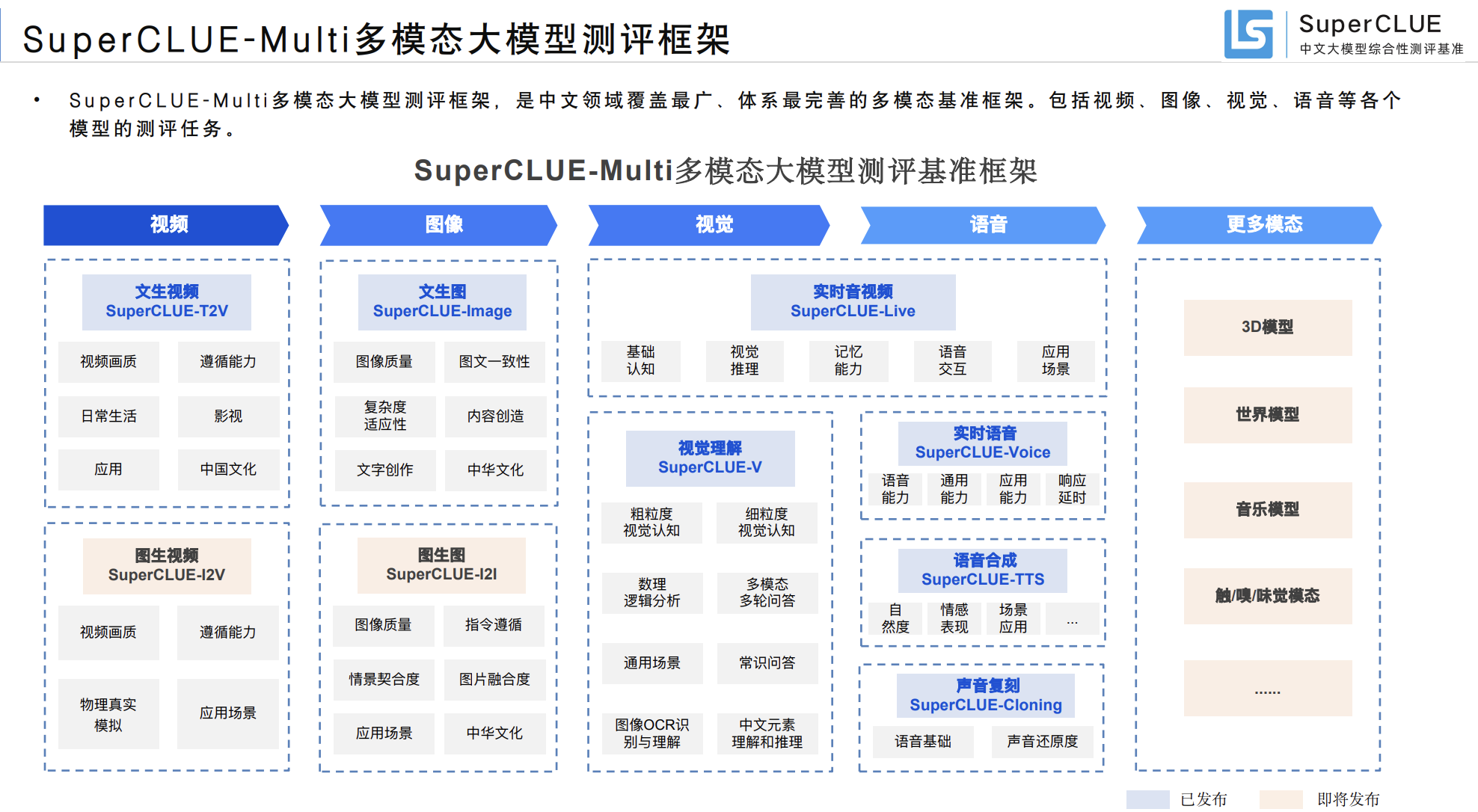
中文语言理解测评基准(CLUE)
内容体系:代表性的数据集、基线(预训练)模型、语料库、论文、工具包、排行榜。
SuperCLUE使命:精准量化AGI进展,定义人类迈向AGI路线图 CLUE定位:为更好的服务中文语言理解、任务和产业界,做为通用语言模型测评的补充,通过搜集整理发布中文任务及标准化测评等方式完善基础设施,最终促进中文NLP的发展。